
1. 准备工作#
使用Python实现需求,环境需求比较严苛,所需要的主要依赖:
Requirements
- dlib 由 C++编写,提供了和机器学习、数值计算、图模型算法、图像处理等领域相关的一系列功能
- face-recognition 已经经过训练成熟的识别人脸的工具
- imutils 用来操作系统文件和文件夹
- Opencv是用来操作视频流,并将视频流转换格式
1.1 环境搭建#
通过 pip 进行安装,在使用 pip 进行安装时,应该注意切换到国内源进行下载,提高下载速度,下面分享一下当前国内的 pip 源:
通过 Anaconda 进行安装,但是需要注意的是在 Anaconda 的资源中并没有face-recognition,需要使用 pip 安装。在安装中可能遇到问题因此在此分享我的环境,分别在 Windows 和 Mac 环境下进行测试。
Mac 环境
- Python 3.8
- dlib 19.20.0
- cmake 3.18.0
- face-recognition 1.3.0
- imutils 0.5.3
Windows 环境
- Python 3.6
- dlib 19.7.0
- cmake 3.18.0
- face-recognition 1.3.0
- imutils 0.5.3
在 Windows 环境中安装dlib如果通过 pip 安装遇到问题,可以直接下载对应版本的Whl文件,使用pip install dlib-19.7.0-cp36-cp36m-win_amd64.whl命令进行安装。
2. 素材展示#
环境搭建完毕后,该项目的目的是捕捉人物在视频中出现并记录相应时间。首先让我们熟悉一下该小项目的测试素材:
- 目标人物的照片
- 存在目标人物的测试视频
2.1 目标人物的照片#
1.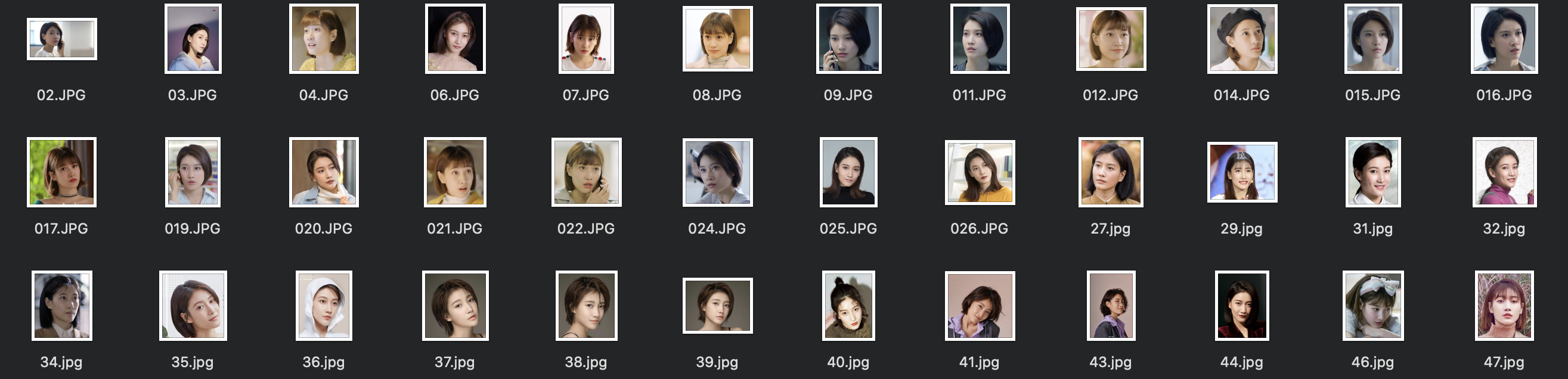

在本项目的需求中只存在一个目人物,照片数量越多越好,数量在 30-80 之间就可以基本实现误差度较低的识别精度,但是需要注意的是照片中应只存在一人,且表情应该尽量丰富,照片不能过于单一。
2.2 测试视频#

3. 实现流程#
在视频中实现特定人物的人脸识别,需要主要两个步骤:
- 对素材中照片进行编码,将每一张照片转换为一个含有 128 个元素的 1 维数组

- 识别视频中对人脸,转换为数组与目标数组进行比对,确定是否匹配,完成识别。

3.1 编码照片#
# 导入模块
from imutils import paths # 操作文件
import face_recognition # 识别人脸并编码
import pickle # 使用pickle文件形式储存节省空间
import cv2 # 操作视频流
# 获取照片
print("[INFO] quantifying faces...")
imagePaths = list(paths.list_images("./dataset")) # dataset为储存照片文件夹
# 初始化储存所有照片编码
knownEncodings = []
# 遍历每张照片并编码
for (i, imagePath) in enumerate(imagePaths):
print("[INFO] processing image {}/{}".format(i + 1, len(imagePaths)))
# 加载图片,转换为RGB模式
image = cv2.imread(imagePath)
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 识别人脸并返回位置
boxes = face_recognition.face_locations(rgb, model="hog") # model 可以选择 cnn 或 hog
# 编码照片并储存
encodings = face_recognition.face_encodings(rgb, boxes)
knownEncodings.append(encoding)
# 写入照片的编码
print("[INFO] serializing encodings...")
data = {"encodings.pickle": knownEncodings}
with open("encoding_face.pickle", "wb") as f:
f.write(pickle.dumps(data))
在编码照片时要注意模式的选择:
如果你有 GPU,可以选择卷积神经网络(CNN),因为要消耗大量的计算力。
如果你和我一样使用 CPU,选择方向梯度直方图方法(HOG),大大地提高计算速度,处理 30 张照片大约消耗 3-5 分钟。
将所有照片编码完成后,结果文件可以在后续不同视频中一直使用,如果要添加更多照片进行检测,那么应该重新进行编码。此外还可以采用免费的 GPU 使用例如Google Colab和Kaggle。
3.2 视频识别#
采用Opencv处理视频流,一帧一帧进行操作。
在视频实时处理过程:

在视频处理过程中需要注意的是三个全局参数的选择:
- THRESHOLD = 0.5 比较视频中人脸和目标人脸是否相同,默认为 0.6,越小越严格
- FILTER_STANDARD = 0.6 此阈值为视频中人脸匹配目标所有照片的比例,越大越严格
- FRAME_STEP = 20 跳帧操作,加快视频处理时间,本视频中 1S 大约 24 帧,最好保证时间连续。
其次仍需注意编码过程中方法的选择,CNN 适合比较适合 GPU 计算。
3.3 结果文件#
将每一帧的处理结果写入文件当中,输出结果中有姓名和出现时间,后续可以对根据结果对视频进行处理。
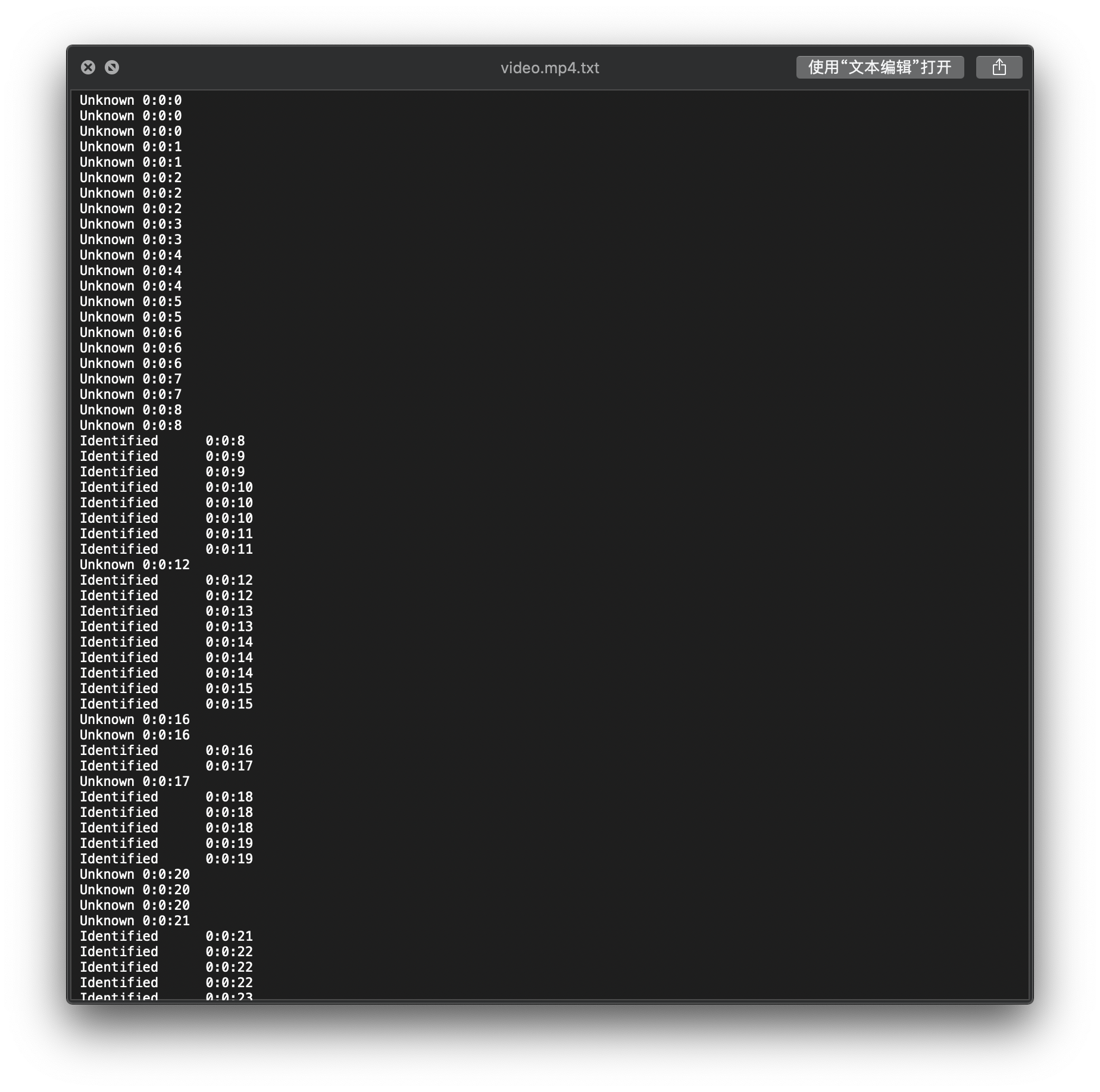
4. 总结#
4.1 可以提高的地方#
在整个实现过程中需要考虑对是硬件和软件的结合,最大程度地满足要达到的需求,在边学边做的过程当中,逐步摸索虽然初步解决了问题,但是还有很多可以改正和深挖的地方。
首先本篇博客代码使用硬编码,这样好处是方便一些,但是不适合分享和复现,同时对文件结构有很高要求,我的文件结构如下:
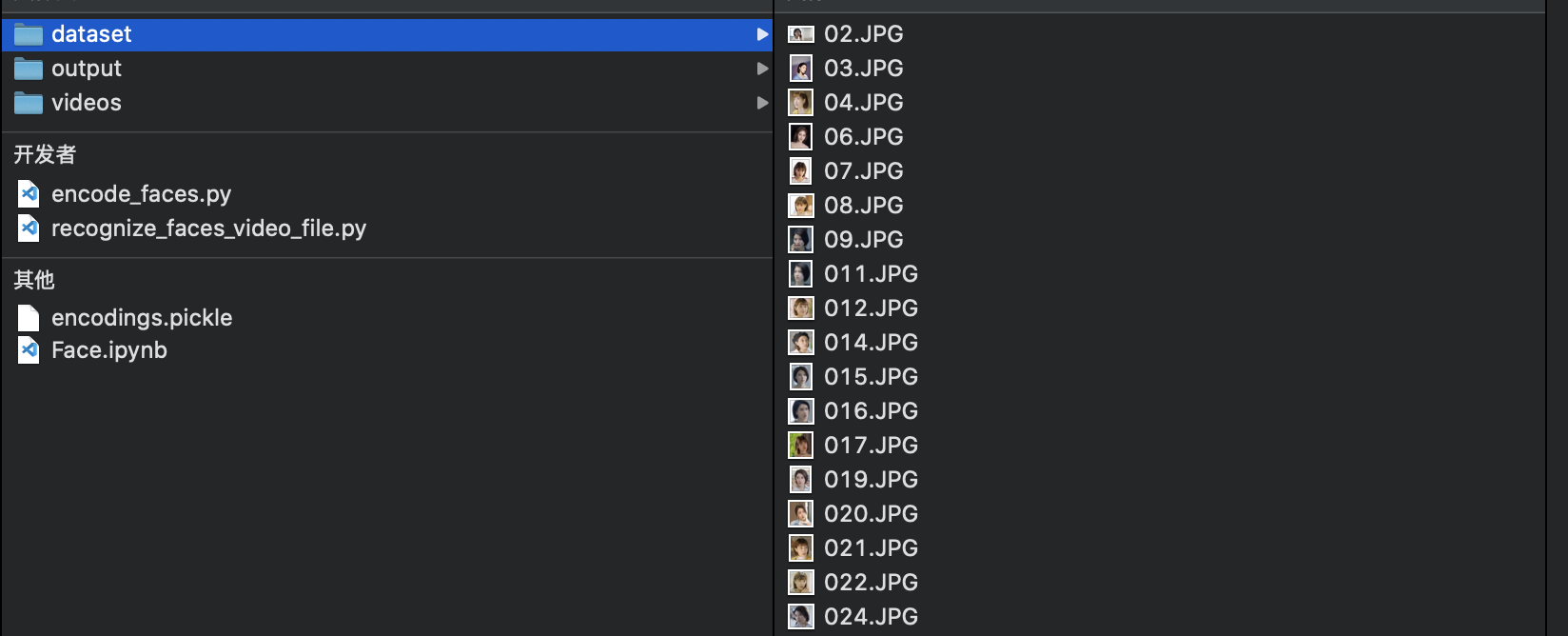
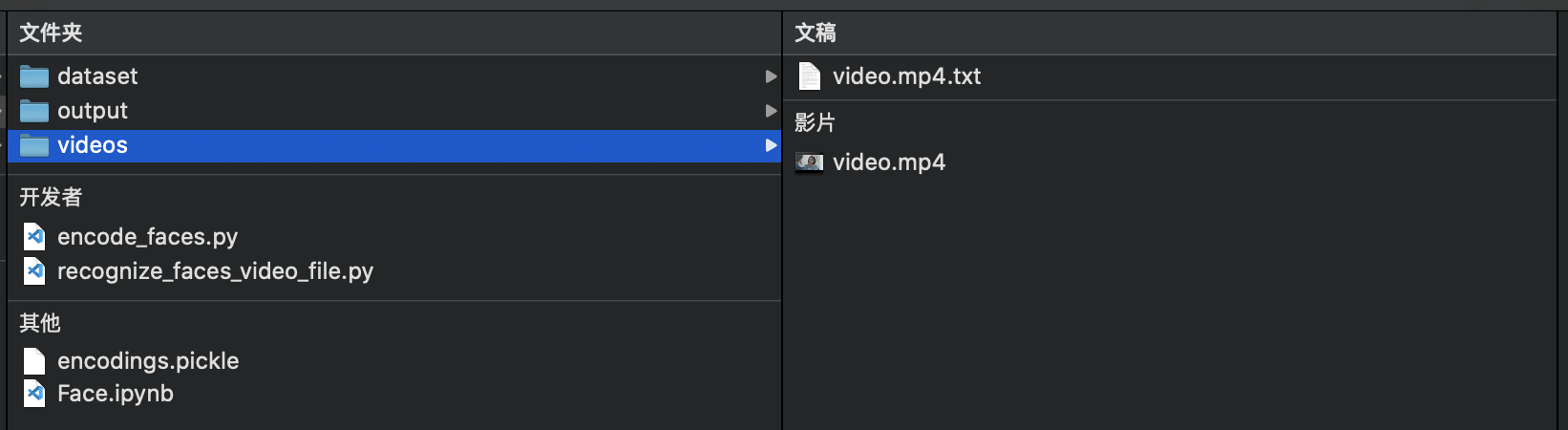
后续可以改为命令行获取参数,令代码更加灵活。其次可以修改代码使其能够同时处理多个视频。
在全局参数的选择也存在些许问题,我并没有找到最适合的参数,可以从结果图片看出在识别的过程中存在错误,我认为有两种解决办法:
- 增加目标编码照片数量,在实现当中使用大约 40 张照片,并且表情比较单一,如果后续可以丰富相应照片,就会避免错误的识别。
- 修改参数,可以结合最大似然估计选择合适的参数。
4.2 收获#
在边学边做的过程中,了解视频与图片处理方法和概念。站在巨人的肩膀上,利用已经有的轮子实现。但是也不能沉浸于此,还是要增强统计相关的知识。
最后,在此记录实现过程,便于后续参考。并且记录遇到问题以及解决办法。